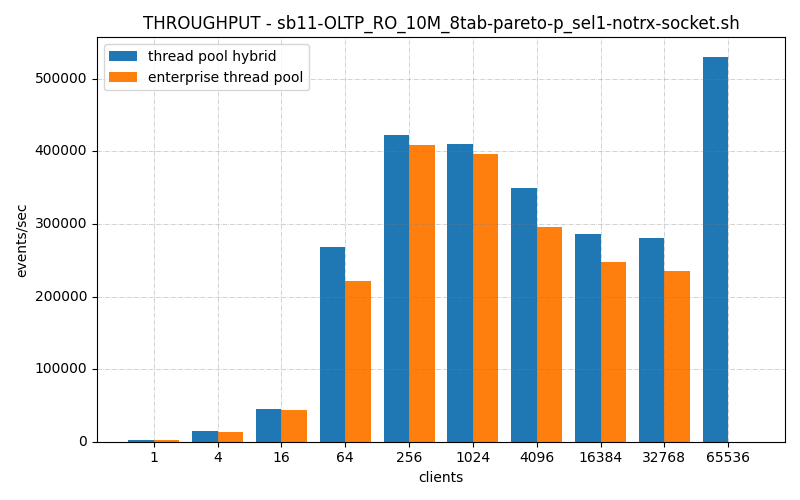
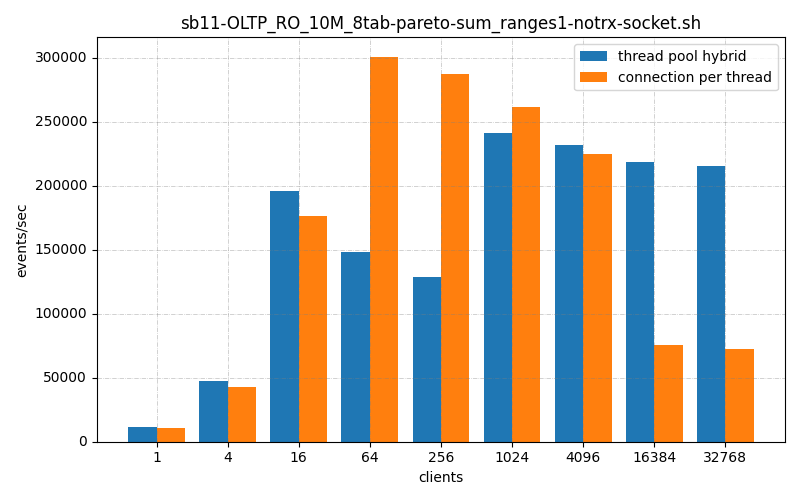
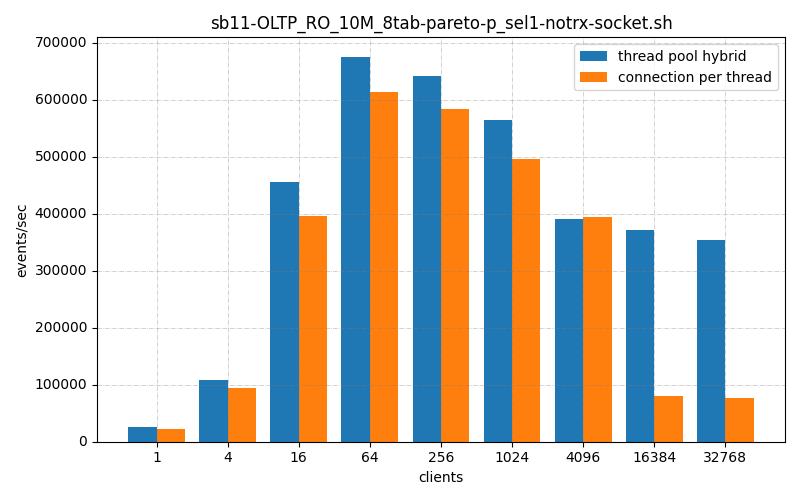
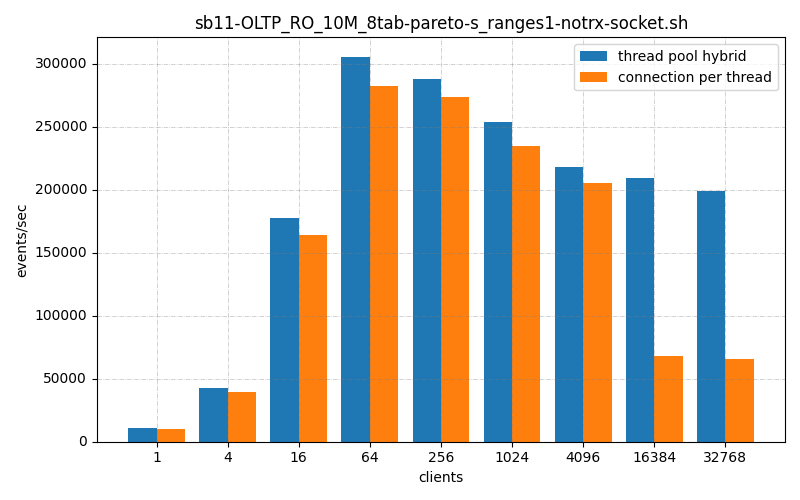
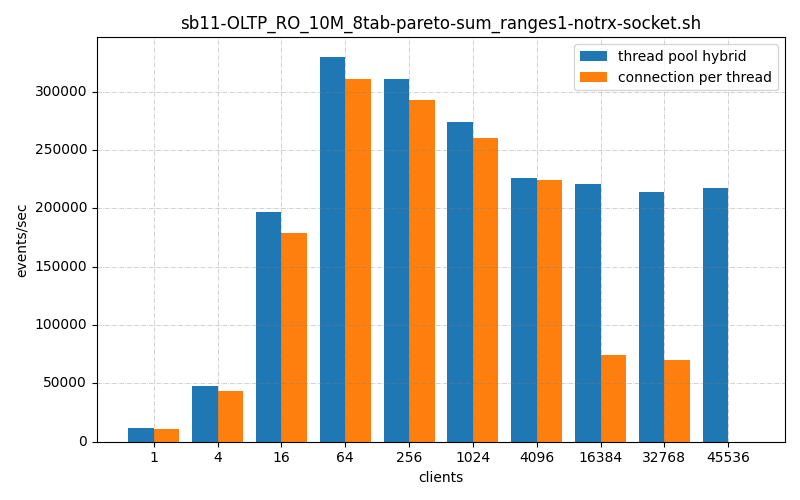
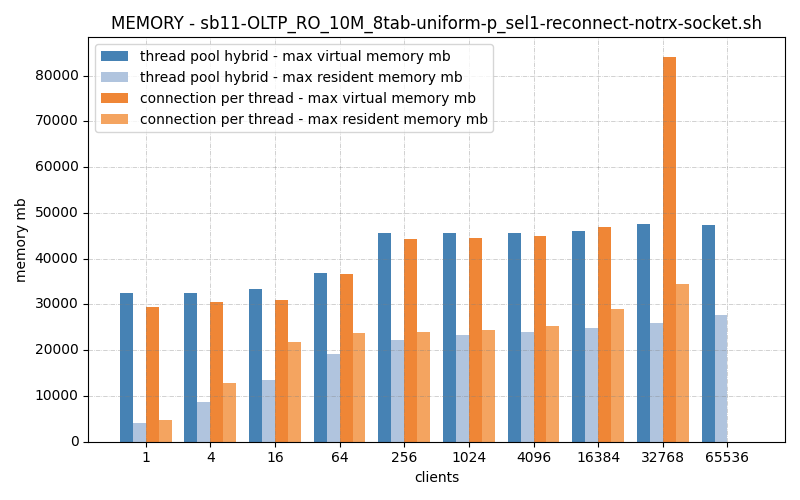So previously we’ve seen my thread pool, hybrid versus connection per thread handler and mine is lighter weight, faster and more scalable. But what about against the Enterprise-edition thread pool connection handler? The one you can’t get the source for and must pay licensing fees to run it in production?
A little background: I wrote the first version of that enterprise thread_pool way back in 2006-07 when I worked for MySQL AB. And it was a significant advance in that that it allowed so many more connections, but the code was a lot slower on low connection counts. Also as that was nearly 20 years ago and it’s been sold as close source since (it was the first close source server side component ever sold by MySQL). It was also one of the things MySQL AB was contractually obligated to produce before Sun Microsystems would purchase MySQL. Idk why, and I wasn’t told it, but it was made clear to me that this was very important code.
Anyway how does my thread pool evented Io connection handler benchmark against this nearly 20 year old thread pooled evented io connection that is “Enterprise” ready?
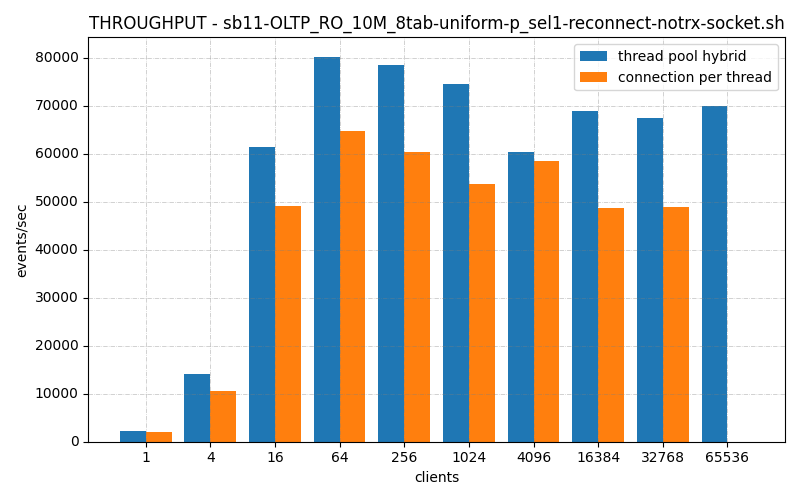
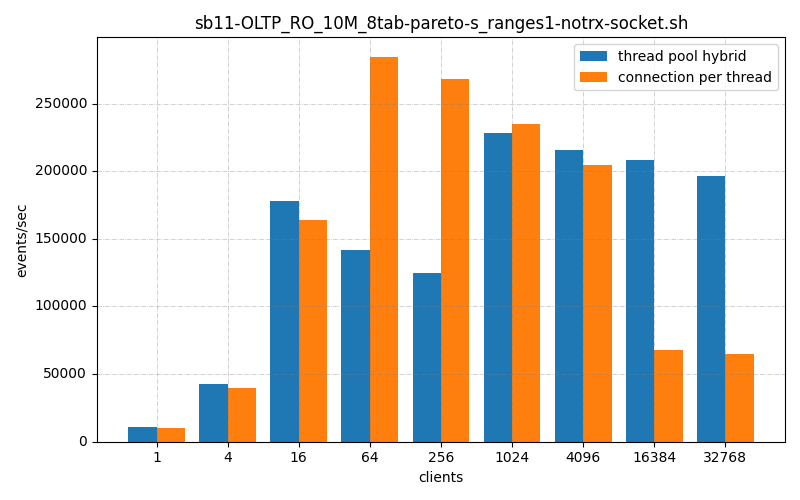
The ThrustDB thread_pool_hybrid connection handler is faster or about the same than the default connection_per_thread handler, in all thread ranges, On low connection counts it’s somewhat faster, on high connection counts it’s a lot faster.
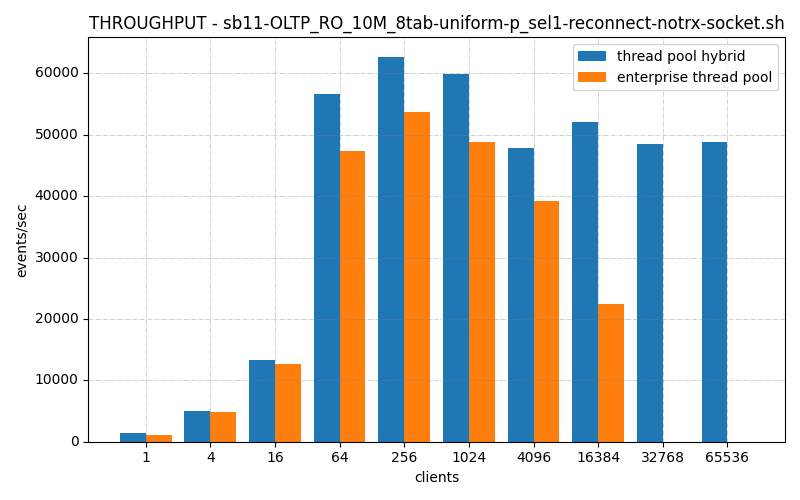
…in the reconnect case. Because it connects and disconnects so many times, it’s like 4 per round, and there are many many rounds per client per test stage.
When a thread comes out of epoll _wait (...) or poll(..) with a network event, it’s gets an event mask, but I wasn’t checking for error, or in this case a client hang-up, just that we got an event, and letting it fall back to normal processing to figure out what to do. But that requires calling into somewhat expensive code, and a somewhat expensive kernel call to tell what’s wrong, when the kernel already told us. All that adds up to slowness, we could have just handled the hang-up when we got it.
So I added the code to do shutdown or error handling when epoll/poll tells us, and forgetting the normal processing. It results in a huge speed up in this benchmark.
New code:
NOTE: Wrong graph was shown earlier. Now corrected.
Old code:
Looking much better on its worst benchmark! The other non-reconnect benchmarks I’m running them now look better as well, but not that much better.
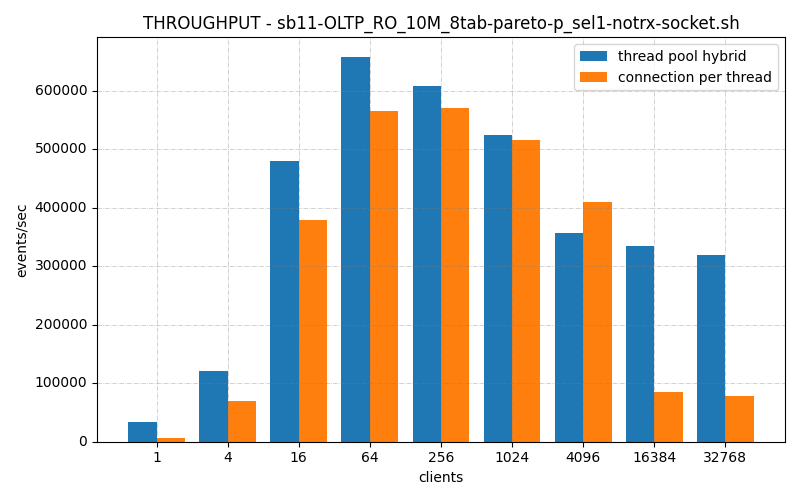
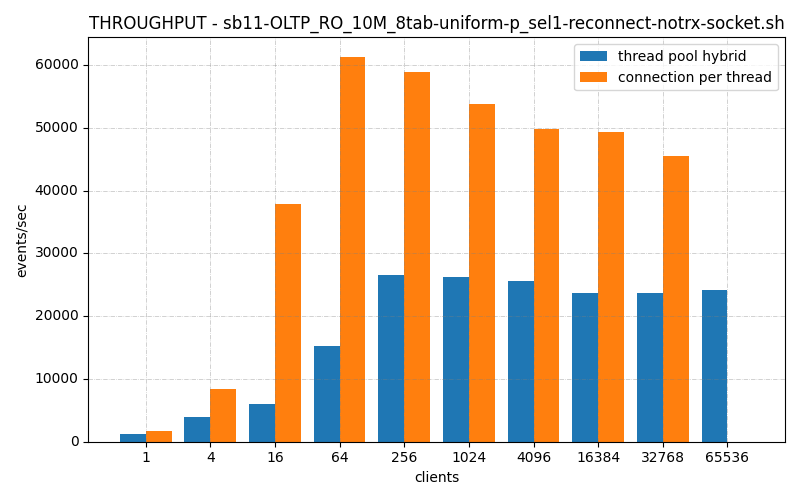
In one of the BMK benchmarks I’ve run, thread_pool_hybrid is significantly slower than connection_per_thread. To whit:
Now while this has the advantage of being being able to host 65536 clients while vanilla mysql crashes, it’s throughput is slower throughout the range of clients until then.
This benchmark is a reconnect case, each client connects, makes a query and disconnects, at least 4 times (maybe more, I’m not sure), which reveals a slowness in my connection handler. Either it’s slow to create connections, or slow to shut them down.
Let’s see if the other graphs give any insights.
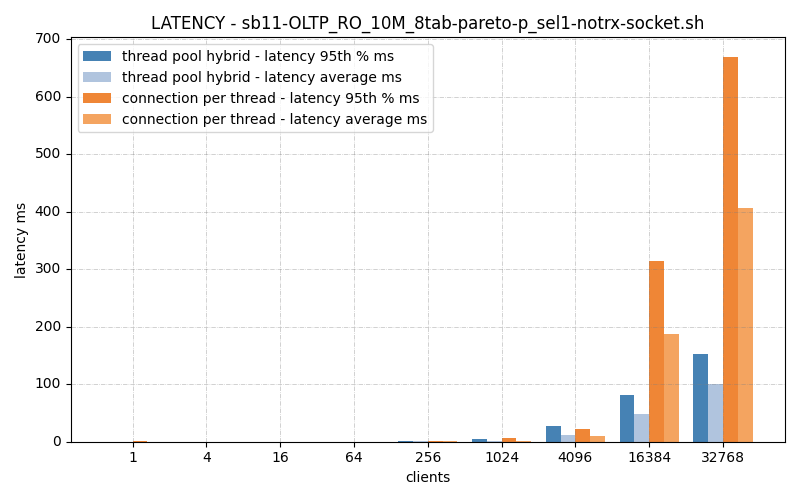
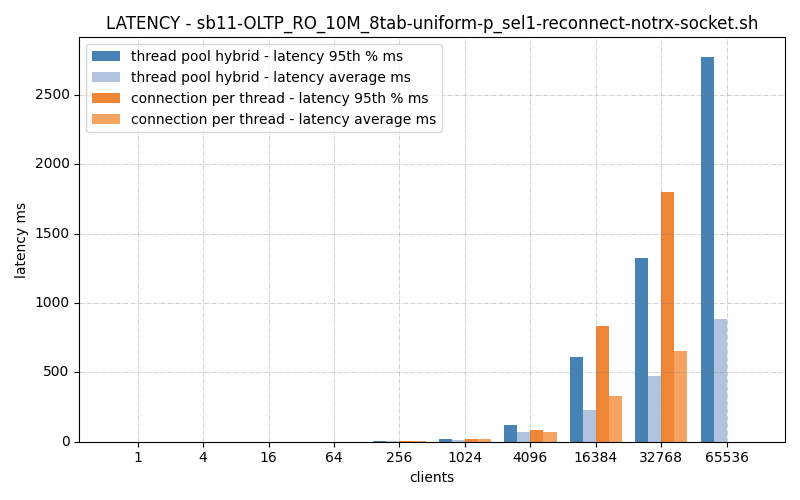
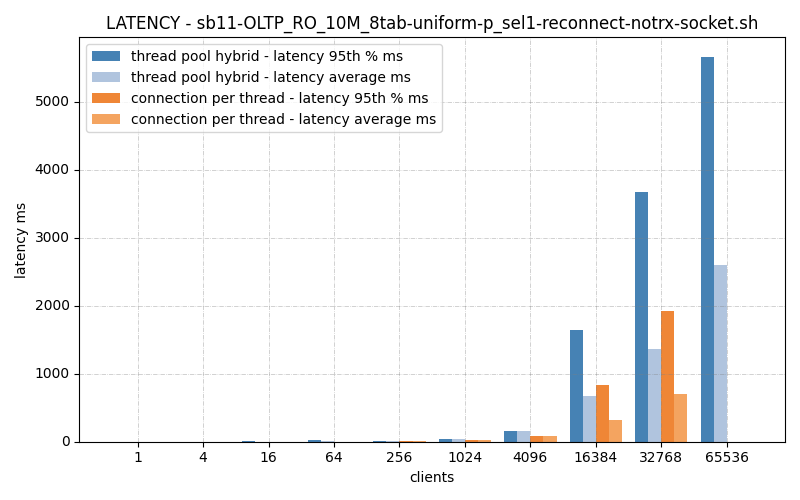
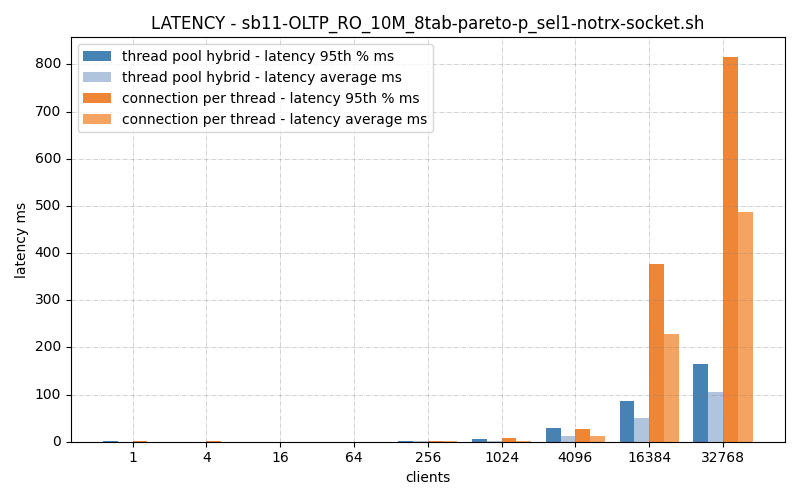
Latency just say ‘yup, you’re slower. Dang.
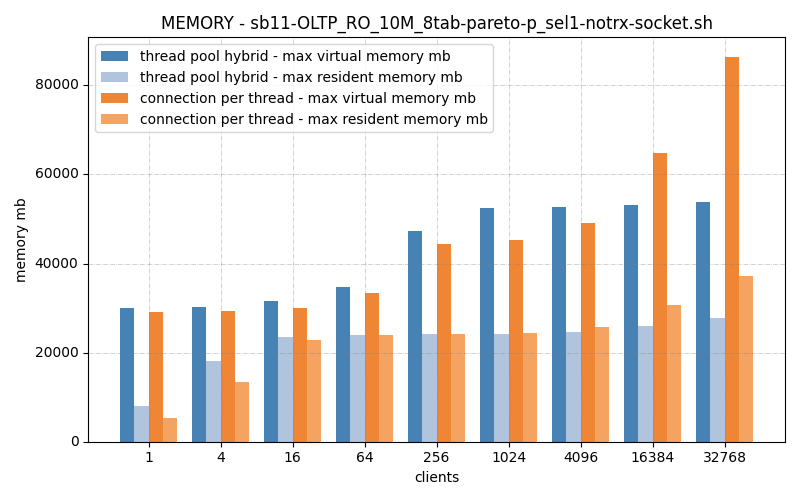
Memory is roughly equal, but connection_per_thread starts to blow up at 32768, which is likely why it dies before it finishes the test, OOM.
CPU is greater for the life of the connection_per_thread handler, but that’s what I’d expect as it’s got around 2x throughput, it’s using more CPU because its doing more work.
So either my connection handler is slow to connect, or slow to disconnect. I haven’t figure out which yet, and why. LMK if you have any ideas.
The first component of ThrustDB I’m delivering is the custom Thread Pool connection handler, named Thread Pool Hybrid (get it here). It’s Linux only, uses no dynamic memory allocation (though epoll_ctl ADD uses red black trees), and can handle a very high number of clients with very little slowdown. And can be used with any modern MySQL system
When compared to the default connection-per-thread handler that ships with MySQL community edition, Thread Pool Hybrid allows up to 10x or more active clients with little slow down in throughput. It uses far less memory per connection (connection-per-thread requires a dedicated thread w/ runtime stack, using memory and resources that can better be used by a smaller number of executing threads.)
However, I’ve discovered one of the disadvantages of the using epoll is an inherent latency when the thread count is relatively low, again reducing throughput.
I benchmarked the performance of vanilla MySQL 8.0.42 both with and without my plug-in connection handler. I used the BMK-kit found on Oracles community downloads and ran some of the 10million 8 table Pareto distribution tests. These were read only tests that tested the scalability without worry about disk IO (both read and write). What I found was a bit troublesome.
As we can see, Thread Pool Hybrid kept up with connection per thread until somewhere around 64 clients, and then begins to catch up around 1024 clients.
We see similar number with other tests:
Also
Well this isn’t the home run I was hoping for!
It’s definitely better on the high and, and keeps pace or better on the low end. But from 64 – 1024 clients, it’s lacking.
Enter the HYBRID model!
So the thing is epoll is very scalable on the high end of clients, and on the low end it is very comparable to connection-per-thread, but there is a middle ground where it lacks, badly. Which gave me an idea, why not, until the thread pool has more connections than threads, use regular poll(...), and when one more connection comes in, all the threads waiting on poll instead revert back to epoll_wait(...) ? So with that in mind I created the hybrid thread pool.
And it works beautifully.
Now this is what I’m talking about!
As the connection count move up past the max threads per pool, the thread pool automatically changes from keeping single threads monitoring a connection, to switching to all the waiting threads switch epoll. Threads actively servicing a connection switch will to epoll once they’ve completed their query.
Once a thread is in epoll_wait(...) it can get an event from any connection in that thread pool, so that if the connection count drops down below the maximum threads, it handles the io of the connection and converts to listening to the connection via poll(...). In this way it preserves performance on the low to mid end and scalability on the high end.
Ok, that’s the basic introduction to the thread_pool_hybrid. Feel free to mail to ask me any questions (me@damienkatz.com). Next I will write about some found weirdness and also how you can contribute to this project or to ThrustDB as a whole. Stay tuned…
What is ThrustDB? It’s distributed, MySQL compatible DBMS that is designed to run in the cloud (AWS, Azure, etc) and be deployed, run and monitored by the same engineers who write the code that makes it work.
Open source DBMS’s have a problem, if anyone can get the code and build it themselves, how do the developers of it make money? Traditionally they don’t make nearly as much as they’d like, and you get all sorts of weird things like special enterprise editions and special monitoring modules, etc that they actually charge for. And if it’s too reliable and works too well, then the customer’s incentive to pay drops dramatically. It just works, why pay?
Thrust! The stuff that makes jet airplanes go.
Did you know that most commercial airlines don’t own the jet engines on their planes? They don’t even rent them. “What?” you may ask, how do the jet engine manufacturers actually make money then? It’s easy. The airlines pay for the “thrust” the engines provide! Yes, really. They pay for time in the air (Power by the Hour) and time in the air means the jet engines are operational. The jet engine is easily the most complex part of the airplane, the most safety critical, and the thing that makes it go. If the engine is operating sub optimally, things get expensive quick.
So instead an airline will contract out with a jet engine manufactures, usually General Electric Aerospace, or their subsidiary CFM International (which together hold 55% of the commercial jet engine market) to provide the jet engines. They install the engine, maintain the engine and replace (as needed) the engine. They designed and built the engine, so they know best how to make it sing. That airline pays for the jet engine’s time in the air, so f the plane is flying, both the airline and the jet manufacturer are getting paid. The interests of the airline and the jet manufacturer are aligned. As long the engine works agreed specification, the airline is happy. As long as the plane is flying, the jet manufacturer is happy. No unnecessary upgrades, no waiting for things to break and then asking for $$$ to fix it. Just smooth operation with few failures or problems.
And so that’s where the name ThrustDB comes from, as the most complex and difficult to maintain system in any companies IT stack, the deployment, monitoring, disaster recovery, etc happens by the same people who wrote the code that makes it work. We make what makes your application go.