…in the reconnect case. Because it connects and disconnects so many times, it’s like 4 per round, and there are many many rounds per client per test stage.
When a thread comes out of epoll _wait (...) or poll(..) with a network event, it’s gets an event mask, but I wasn’t checking for error, or in this case a client hang-up, just that we got an event, and letting it fall back to normal processing to figure out what to do. But that requires calling into somewhat expensive code, and a somewhat expensive kernel call to tell what’s wrong, when the kernel already told us. All that adds up to slowness, we could have just handled the hang-up when we got it.
So I added the code to do shutdown or error handling when epoll/poll tells us, and forgetting the normal processing. It results in a huge speed up in this benchmark.
New code:
NOTE: Wrong graph was shown earlier. Now corrected.
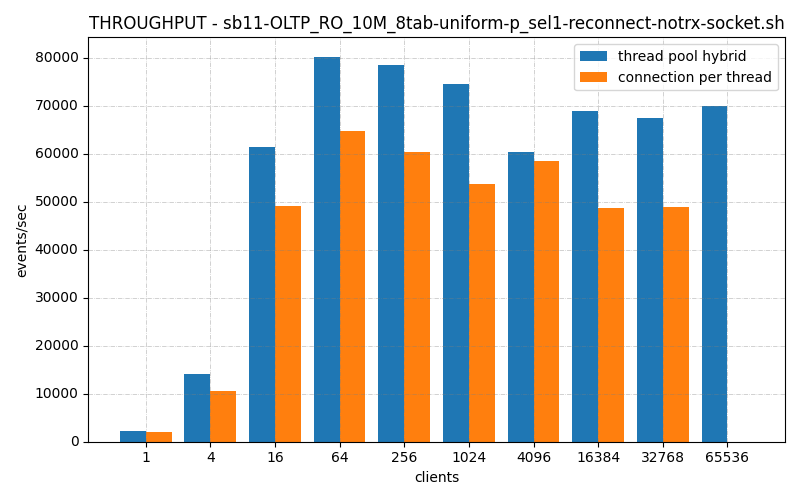
Old code:
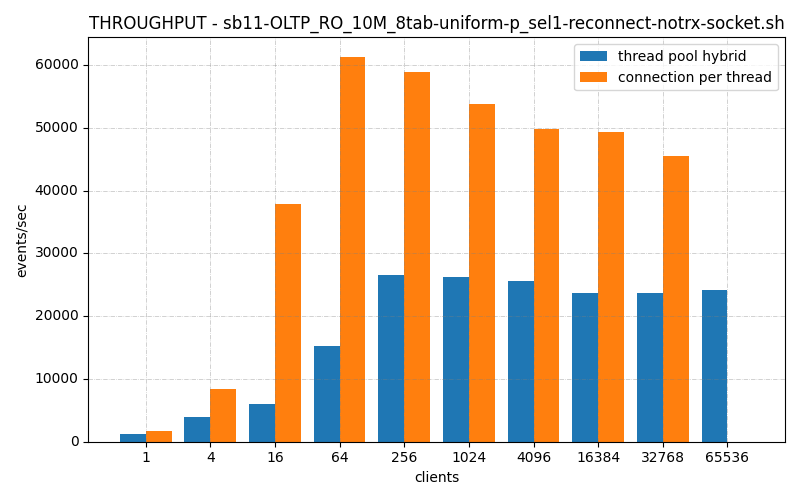
Looking much better on its worst benchmark! The other non-reconnect benchmarks I’m running them now look better as well, but not that much better.

Leave a comment